
À l’heure de l’IA, de la robotisation de blocs opératoires, ou de dossiers patient 100 % numérique, l’exploitation des données de santé est un sujet devenu presque banal, voire invisible (nous sortons mécaniquement notre carte vitale, nous cochons mécaniquement une case de consentement à l’arrivée à l’hôpital…). C’est pourtant toujours un sujet stratégique dans le domaine médical.
La base de données de l’Assurance Maladie sort du lot sur ce sujet. C’est une mine d’informations sur la santé de nos concitoyens, et l’une des plus grandes au monde1. Via les analyses épidémiologiques, elle permet d’entrevoir un avenir où les maladies pourraient être prédites avant leur apparition, et où les parcours de soins seraient optimisés pour chaque personne. Ce défi repose sur l’ingénierie de l’analyse de données massives, où des algorithmes d’apprentissage automatique (machine learning) rencontrent des contraintes éthiques et sociétales. La question est de savoir comment nous pouvons exploiter ce “trésor national” tout en répondant aux attentes des citoyens. Cet article explore ces enjeux à travers un exemple concret.
Le SNDS, une source précieuse pour les analyses épidémiologiques
Le Système national des Données de Santé (SNDS) rassemble des données de santé de 68 millions de citoyens français2. Elles proviennent de plusieurs sources : les remboursements de soins par l’Assurance Maladie (consultation chez le médecin, délivrance en pharmacie…), les données hospitalières (hospitalisation, opération…), et les causes médicales de décès (certificats médicaux…). Le SNDS permet de suivre dans le temps et dans l’espace (sur le territoire national) les étapes de soins de chacun, et donc d’identifier des tendances épidémiologiques (à noter qu’épidémiologie ne concerne pas que les épidémies, type grippe, VIH ou Covid, mais plus largement toute cohorte de patients avec une pathologie)3. Cette perspective permet de suivre l’efficacité de politiques publiques et d’améliorer le système de santé.
Par exemple, la question s’est posée pour l’Assurance Maladie de mieux anticiper les complications du diabète, maladie chronique qui touche environ 4 millions de Français. Pour cela, elle a lancé un appel d’offres pour missionner un bureau d’études externe et indépendant qui serait capable d’utiliser cette base de données pour y répondre (cf. plus bas).
Comprendre le marché de niche de la donnée de santé
L’année 2017 a marqué un tournant dans l’utilisation des données du SNDS en France. L’article 193 de la loi de modernisation de notre système de santé du 26 janvier 2016, qui instaure le SNDS dans sa version encore en vigueur en 2025, est alors entré en application. Il permet aux bureaux d’études privés de mener des études épidémiologiques, alors que ces données étaient auparavant réservées à des acteurs publics clés (Assurance Maladie, ARS, INSERM, HAS, ANSM, hôpitaux…). son accès est depuis 2019 géré par une agence publique nouvellement créée à l’époque, le Health Data Hub (HDH). Le HDH centralise les demandes de tous ceux qui souhaitent y accéder, et assure un cadre de sécurité et de régulation en collaboration avec le CESREES (comité en charge d’évaluer la pertinence et le fondement de chaque demande) et la CNIL. Depuis 2017, les demandes d’accès émanent d’une grande variété d’acteurs4 :
- Les établissements de soins : près de 50 % des demandes (ex. APHP, CHU régionaux)
- Les industriels de santé : environ 20 % des demandes, surtout portées par des laboratoires pharmaceutiques (Roche, Sanofi, Pfizer et BMS en tête). Ils exploitent les données pour évaluer l’efficacité de traitements et documenter des dossiers réglementaires.
- Les universités et organismes de recherche : responsables d’environ 10 % des demandes d’accès.
Dans cet écosystème, les bureaux d’études (regroupé sous l’acronyme anglais de CRO, “Contract Research Organization”) jouent le rôle de responsable de mise en œuvre (RMO) des études. Parmi eux, 5 acteurs (Heva, IQVIA, CEMKA, Stève consultant, Median Conseil) se partagent 63 % du marché (en nombres d’études réalisées), et une vingtaine d’acteurs ont déjà mené plus de 10 études4. Ces entreprises accompagnent les industriels (laboratoires pharmaceutiques et fabricants de dispositifs médicaux) et les institutions dans la conception, l’analyse et la valorisation des données.
L’accès au SNDS est cependant jalonné de quelques défis : des coûts d’études substantiels pour de petites structures ; des délais de traitement longs, liés aux processus d’approbation par le CESREES et la CNIL, bien que des “méthodologies de référence” simplifient certaines demandes. Le temps moyen pour obtenir une extraction de données pour un projet est de 10 à 14 mois.
À noter que la liste de toutes les études approuvées par le HDH pour utiliser le SNDS est publique et accessible en ligne5.
Un projet concret sur des données de santé : évaluer l’impact d’un programme d’accompagnement de patients diabétiques
Présentation et objectifs du programme Sophia
Lancé en 2008 par l’Assurance Maladie, le programme Sophia s’appuie sur les principes du “disease management”, une approche éprouvée dans plusieurs pays pour optimiser la prise en charge des maladies chroniques. Son objectif est de limiter les complications graves du diabète (amputations, insuffisance rénale, complications cardiovasculaires), tout en améliorant la qualité de vie des patients et en maîtrisant les dépenses de santé (voir Figure 1). Ce service propose un accompagnement personnalisé, associant conseils, supports pédagogiques et échanges avec des conseillers en santé.
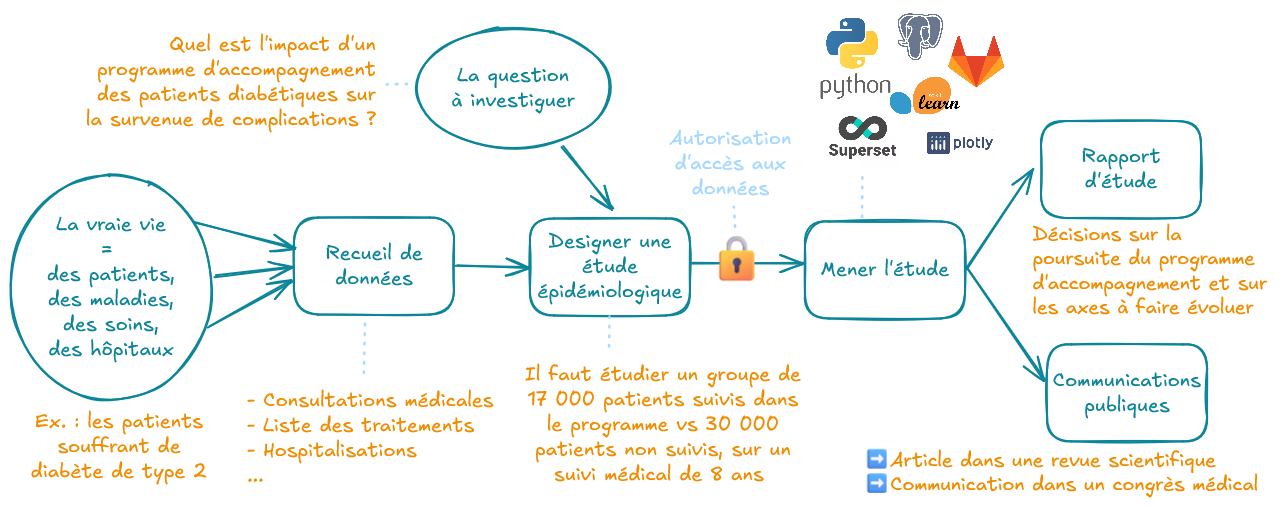
Méthodologie de l’évaluation
Pour mesurer l’impact long terme du programme, les données de suivi des patients ont été prises sur 8 ans (grâce à l’antériorité du SNDS, qui remonte jusqu’en 2008 avec un bon taux de complétion). L’objectif était de répondre aux questions médico-économiques suivantes : le programme améliore-t-il les indicateurs de suivi médical recommandés (ex. visite annuelle chez un podologue) ? A-t-il un effet mesurable sur les complications graves et les hospitalisations ? Quel est son impact économique sur les dépenses de soins ambulatoires et hospitaliers ?
Pour apporter une réponse qui soit fiable statistiquement et méthodologiquement, il faut typiquement étudier plusieurs cohortes de patients dans ce genre de situations : (a) les patients adhérents au programme (population cible, environ 17 000 patients), (b) les patients non-adhérents, mais qui étaient éligibles (environ 30 000) (c) et de patients témoins (des millions), qui ont la maladie, mais n’ont pas eu accès au programme (géographiquement par exemple). Ce travail de “design épidémiologique” se fait en collaboration multidisciplinaire entre un épidémiologiste, un data engineer, un data scientist et un expert médical de la pathologie (voir encadré ci-dessous).
Quelle différence entre un data engineer et un data scientist ?
Le data engineer prépare le terrain, s’assure que tout est prêt techniquement dans l’infrastructure de données (c’est comme préparer les décors, les caméras, et les lumières pour un film).
Le data scientist crée l’histoire et fait parler les données pour que le public comprenne (c’est comme raconter une belle histoire à l’aide du film tourné).
Les deux travaillent main dans la main pour produire un film réussi !
Solution mise en œuvre
Une fois le design de l’étude établi, la partie technique du projet est mise en œuvre en 3 étapes :
- Il faut trouver tous les soins des patients retenus pour l’étude (le SNDS est une base de données relationnelle composée de plusieurs centaines de tables et articulée autour de dizaines de clés de jointure). Ce travail est codé par un data engineer spécialement formé à ces données.
- Ensuite, il transforme chaque donnée, qui a été initialement recueillie dans un but de remboursement, vers une information avec un sens médical. Par exemple, une consultation chez un médecin généraliste génère plusieurs entrées dans la base : la part remboursable par la sécurité sociale (70 % de 30 €), la participation forfaitaire (2 €), voire la gestion du tiers payant. La reconstruction d’une base de données orientée vers le “soin” est probablement la composante la plus complexe du SNDS, et qui demande une double connaissance, technique (en gestion de bases de données) et métier (compréhension du système de santé français, et de ses évolutions au fil des décennies).
- Enfin, le travail d’un biostatisticien ou data scientist commence. Il/elle ouvre la boîte à outils (statistiques classiques, bayésiennes, IA, machine learning, deep learning, process mining, analyses de survie …), et sélectionne le meilleur en fonction de la problématique.
Dans le projet Sophia diabète, c’est une méthode de process mining qui a été utilisée6 (i.e., technique basée sur la théorie des graphes, les les modèles d’automates et l’apprentissage automatisé). Cette technique permet de modéliser le concept de “parcours patient”, c’est-à-dire l’enchaînement ordonné d’étapes de soins qui ont lieu au cours du temps. Il s’agit de retracer les parcours des patients diabétiques en examinant leurs interactions avec le système de santé : consultations, hospitalisations, bilans médicaux, prescriptions, etc. Or, l’histoire de chaque patient est une frise chronologique quasiment unique quand on regarde chaque soin reçu au jour près sur 8 ans de suivi (la combinatoire est grande !). C’est là qu’un algorithme de process mining est nécessaire : il a analysé la frise chronologique des 17 000 patients pour en dégager les parcours types sous forme de flux (ex. visite chez le généraliste tous les semestres, avec délivrances du traitement dans la semaine suivant chaque consultation), mais aussi les déviations les plus fréquentes (patients qui n’ont pas de visite de contrôle annuelle chez l’ophtalmologue alors qu’ils ont vu par ailleurs un podologue). Cette modélisation est ensuite utile pour prédire la probabilité de survenues des complications en fonction du parcours suivi par un patient.
Résultats et impact
Les résultats d’une telle étude sont présentés dans un rapport formel et détaillé7. En quelques chiffres, cette étude rétrospective a montré que les patients accompagnés par Sophia étaient 25 % moins susceptibles de développer des complications graves lorsqu’ils suivent le parcours type. Le programme a aussi réduit les coûts médicaux (-4 %), en évitant surtout des hospitalisations et des traitements lourds, au profit de consultation de ville. Ces résultats ont justifié l’élargissement du programme et fourni des bases pour son amélioration.
Pour les analyses des parcours de soin avec le process mining, la méthode a mis en lumière une différence entre adhérents et non-adhérents qui n’avait jamais été étudiée : chez les patients adhérents, une meilleure régularité dans l’enchaînement des consultations spécialisées est observée (notamment en diabétologie et en ophtalmologie) par rapport aux non-adhérents. L’analyse a aussi montré une réduction des interruptions de parcours, comme l’absence de consultations pendant plusieurs mois.
Au-delà des résultats chiffrés, ce projet nous apporte une perspective intéressante sur le niveau de maturité déjà atteint en France sur plusieurs sujets : le recueil d’une base de données nationale, la mise en œuvre de projets combinant des expertises en épidémiologie et en big data, ainsi que l’utilisation d’algorithmes de data science.
Conclusion
L’ingénierie des données de santé transforme notre manière de comprendre et d’améliorer les parcours de soins. L’exemple du programme Sophia illustre le potentiel d’analyses via l’un des outils du data scientist.
Ces avancées reposent sur une alliance entre expertise technique et vision éthique. Le SNDS, parmi d’autres bases de données de santé, est un outil puissant, mais son exploitation exige une collaboration rigoureuse et une communication transparente pour renforcer la confiance des citoyens. L’accès y est réglementé, mais de façon intelligente, pour permettre à des acteurs compétents et habilités (publics ou privés) d’en extraire de la valeur. In fine, l’ingénierie des données définit déjà les bases d’une médecine plus prédictive, préventive et personnalisée.


La Revue des Mines est produite grâce au temps de ses bénévoles et à ses contributeurs. Pour nous rejoindre, écrivez-nous !
Contribuer

